이 논문은 2015년에 ICCV 학회에 발표된 논문이다. 성능이 크게 좋아지진 않았지만, FCN의 단점을 명확하게 짚고 이를 해결하기 위한 방법을 잘 설명해주었다.
초록
Deconvolution Network은 VGG16를 사용한 Convolution layer 위에 deconvolution, unpooling layer로 구성된 Deconvolution layer를 쌓은 구조이다. 이미지 내에서 추출한 proposal들을 네트워크에 넣어서 얻은 output들을 결합해서 최종적으로 segmentation map을 만들어 내는 형식으로 진행된다.
FCN에서는 압축된 피쳐로부터 갑자기 큰 비율로 (32배, 16배, 8배) upsampling하여 인풋과 동일한 크기의 output을 얻었다. 그 결과 일부 정보가 소실된 거친 segmentation map이 나올 수밖에 없었다.
DeconvNet에서는 아래 두 특징을 통해 FCN의 단점을 어느정도 해결했다.
- deconvolutional network을 깊이 쌓았다
- proposals 별로 prediction해서 합치는 방식 사용
이를 통해 이미지 내 객체의 디테일을 잘 학습하고, 다양한 크기의 객체를 인식할 수 있게 되었다.
그 결과, PASCAL VOC 2012에서 좋은 성적을 냈으며, FCN과 앙상블로 사용했을 때 최고의 정확도를 내었다.
1. 도입
이전 연구
이전 연구에서는 bilinear interpolation을 사용하여 간단히 deconvolution을 했으며, 더 정교한 segmentation을 위해 output map에 옵션으로 Conditional random Field (CRF)이 적용되기도 했다.
FCN의 경우에도 아래 두 가지 단점이 있다.

- Receptive field의 크기가 고정되어 있기 때문에, 단일 스케일의 semantic(의미)만 파악이 가능하다.
- 그 결과, receptive field보다 너무 크거나 작은 객체는 조각나거나 검출되지 않는 문제가 발생한다.
- FCN에서 skip architecture로 해결하려 했으나 근본적인 해결이 아니다.
- 객체의 디테일이 많이 사라진다.
- deconvolution layer의 입력인 label map이 너무 작기 때문에 이로부터 정확한 segmentation map을 얻기엔 손실된 정보가 많다.
- deconvolution이 (깊지 않고) 지나치게 심플하다. (bilinear interpolation 사용)
논문의 Contribution
- Multi-layer deconvolution network를 학습한다.
- Deconvolution, Unpooling, ReLU로 구성
- 학습된 네트워크에 각 object proposals가 넣어져서 instance-wise segmentation이 가능하다
- 각 proposals에 대한 결과는 나중에 합쳐진다
- scale(배율) 문제를 해결하여 더 정확한 결과가 나온다
- FCN이랑 앙상블해서 최고의 성적을 내었다.
3. 시스템 구조
3.1. 구조
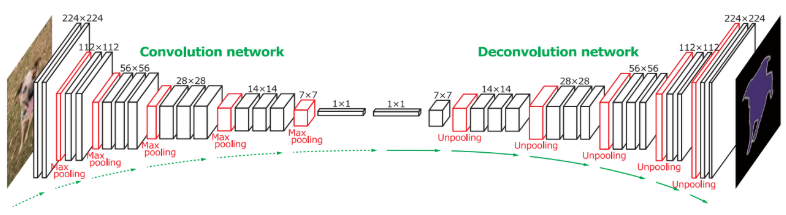
특징을 추출하는 convolution (VGG16) 부분과 객체의 모양을 복원해내는 deconvolution 부분으로 이루어져 있다. (FCN에서 32배, 16배, 8배 세 단계로 키운 것과 달리, 여기에선 convolution이랑 symmetric하게 deconvolution layer를 깊게 쌓음)
네트워크의 최종적인 output은 인풋 이미지와 같은 크기의 probability map이다. (각 픽셀 별로 특정 클래스에 속한 확률을 담고 있음)
3.2. Segmentation을 위한 Deconvolution Network
3.2.1 Unpooling

Unpooling에서는 pooling 했던 위치를 기억해서 크기를 키운다. 그렇지만 그 결과로 sparse한 activation map이 나오게 된다.
이를 Densify하기 위해 Deconvolution이 사용된다.
3.2.2 Deconvolution

Deconvolution layer는 convolution과 비슷한 operation으로 여러 filters를 학습함으로써 unpooling 해서 얻은 sparse activation map을 densify시킨다.
filter를 사용해서 여러 input activation을 하나의 activation으로 연결하는 convolution layers와 달리, deconvolution layers는 하나의 input activation을 여러 outputs와 연관 짓는다.
3.2.3 Deconvolution Network 분석
Unpooling, deconvolution, rectification을 통해 깊게 쌓은 deconvolution network를 사용해서 dense(정교한) 픽셀 별 class probability map을 얻는다.

Deconvolution network의 layer 별로 activation을 시각화한 결과는 위와 같다. 얕은 층에서는 위치, 형태 등 전반적인 큰 형상 정보가 저장되어 있고, 깊은 층으로 갈 수록 복잡한/디테일이 살아있는 패턴에 대한 정보를 가진다. 또한, 배경으로 인한 noisy activation이 propagation을 할수록 사라지고, target의 activation이 증폭됨을 볼 수 있다. Deconvolution layers를 거칠수록 클래스와 관련한 형태 정보를 기억함을 알수 있다.
Unpooling과 Deconvolution이 다른 역할을 한다는 것을 기억하자.
- Unpooling : 이미지 공간으로의 강한 activation을 통해 실제 위치를 추적함으로써 examples과 관련된 특징을 알아냄. 그 결과, 더 좋은 해상도로 객체의 자세한 구조를 파악할 수 있음
- Deconvolution layers : 클래스와 관련된 형태를 학습함. Deconvolution을 통해 이상한 위치에 있는 noisy activation들이 잘 걸러지고, target 클래스와 관련된 부분의 활성화가 증폭된다.
아래는 FCN와 DeconvNet의 결과를 비교한 것이다.

FCN은 더 coarse하고, DeconvNet은 비교적 dense하고 정확함을 볼 수 있다.
3.3 시스템 개요
이미지 내 instance를 포함한 부분을 입력으로 받고, 픽셀 별 클래스를 예측한다.
이렇게 instance 별 segmentation을 해줌으로써 몇 가지 장점이 있다.
- 다양한 스케일의 object를 다룰 수 있다.
- 객체의 디테일을 파악할 수 있다. (고정된 receptive field 방식과 달리)
- 학습 복잡도를 줄여준다 (탐색공간을 줄임으로써)
객체가 있다고 예상되는 각 proposals에 다 네트워크를 적용시키고, 모든 proposals로부터의 outputs를 기존 이미지 공간에 합침으로써 저네 이미지에 대한 semantic segmentation을 얻는다.
4. 학습
네트워크 자체는 아주 깊어서 학습해야 할 파라미터 수도 아주 많다. 그런데 네트워크 크기에 비해 학습 데이터의 수가 적다. 적은 수의 데이터로 깊은 네트워크를 학습시키기 위해 아래 두 가지 방법을 사용했다.
4.1 Batch Norm
Internal-covariate-shift 문제로 인한 local optimum에서 벗어나기 위한 방법이다. Internal-covariate-shift란 학습하면서 앞의 layer가 업데이트되어 layer들의 입력 분포가 계속 바뀌는 현상이다. Layer를 따라 propagation할 수록 분포의 변화가 증폭된다. 모든 convolution, deconvolution layer마다 input distribution을 가우시안 분포로 정규화하는 batch normalization을 사용함으로써 이를 해결하였다.
4.2 Two-stage 학습
네트워크가 커서 학습이 어렵다는 문제는 해결하기 위한 방법이다. 네트워크를 일단 쉬운 examples로 학습을 시킨 뒤, 비교적 어려운 examples로 미세조정하는 방식이다.
- 첫 번째 단계에 사용되는 examples 만드는 법 : ground-truth 정보를 활용해서 인스턴스가 중앙에 오도록 자른다.
- -. 위치와 사이즈 측면에서 변동이 줄어들어 탐색공간을 줄임으로써 적은 양으로도 학습이 용이하게 된다
- 두 번째 단계에서는 object proposals를 사용해서 더 어려운 examples를 만들어 낸다
- -. ground-truth와 많이 겹치는 proposals들이 학습용으로 선택된다. 이를 통해 테스트할 때 proposals의 위치에 강건한 모델을 만들 수 있다.
5. 추론
5.1 Instance 별로 생성된 Segmentation maps 합치기
몇몇 proposals들이 틀릴 수 있는데, 이런 노이즈는 결합 과정에서 없애야 한다. 모든 클래스들의 score maps에서 픽셀 별 최대값 혹은 평균값으로 합치는 것이 좋은 결과를 가져왔다. 기존 이미지 공간에서의 class conditional probability maps는 (1) 혹은 (2)로부터 합쳐진 결과에 softmax 함수를 적용함으로써 나오게 된다. 마지막으로 fully-connected CRF를 output map에 적용해서 최종적인 픽셀 별 라벨링을 한다.
FCN과 앙상블
DeconvNet은 디테일을 잘 잡고, FCN은 보다 대략적인 형태를 잘 잡기 때문에 개괄적인 크기에서 맥락을 파악하기가 좋다. 다양한 크기의 instance가 있을 경우, FCN이 강점이 있기 때문에 두 알고리즘으로부터의 결과를 결합하였다. 한 이미지에 대한 두개의 class conditional probability가 주어졌을 때, 두 output maps의 평균값을 구한 뒤 CRF를 적용하여 최종 결과를 얻었다.
6. 실험
PASCAL VOC 2012 segmentation dataset로 실험한 결과는 아래와 같다.

'딥러닝 > Semantic Segmentation' 카테고리의 다른 글
| BiSeNet V2 : Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation (0) | 2021.08.10 |
|---|---|
| DeepLabv3+ 논문 리뷰 (1) | 2021.03.31 |
| (풀잎스쿨 14기) Deeplab v2 논문 리뷰 (1) | 2021.03.07 |
| Unet 논문 리뷰 (0) | 2021.02.07 |


