anomaly detection에 대해 잘 몰라서 아무거나 찾아서 초록만 정리하는 글입니다 :)
질문이나 틀린 점이 있다면 댓글 바랍니다 ㅎㅎ
시간 순서대로 보시려면 아래 순으로 참고하시길 바랍니다.
3. AnoGAN (17.Mar.2017)
4. Real-world Anomaly Detection in Surveillance Videos(cvpr 2018)
5. Future Frame Prediction for Anomaly Detection - A New Baseline (cvpr 2018)
9. Adversarially Learned One-Class Classifier for Novelty Detection (24.May.2018)
7. GANomaly(13.Nov.2018)
1. MemAE (6.Aug.2019)
6. MVTec AD — A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection (cvpr 2019)
8. Skip-GANomaly (25.Jan.2019)
2. ANOMALY DETECTION BY LATENT REGULARIZED DUAL ADVERSARIAL NETWORK (5.Feb.2020)
1. MemAE (memory-augmented autoencoder)
(6.Aug.2019)

Anomaly detection에 deep autoencoder가 많이 사용되고 있다. 정상 데이터를 학습함으로써, abnormal 인풋에 대해 오토인코더는 더 큰 reconstruction 에러를 만들어 내고, 이것이 anomaly를 찾아내는 criterion이 되었다. 하지만, 대개의 경우 오토인코더가 "일반화"를 너무 잘해서, anomaly까지도 reconstruct하여 detect하지 못하는 것을 볼 수 있었다. 오토인코더 기반의 anomaly detection의 이러한 단점을 보완하기 위해, memory 모듈로 오토인코더를 augment하고, MemAE라고 하는 개선된 오토인코더를 제안한다.
인풋이 주어졌을 때, MemAE는 가장 먼저 encoder로 부터 encoding을 가져와 이를 reconstruction을 위한 가장 관련되어 있는 메모리를 가져오기 위한 query로 사용한다.
학습 단계에서 memory의 내용은 업데이트되고, 정상 데이터의 요소를 표현할 수 있게 된다. 테스트 단계에서는 학습된 메모리가 고정되며, 정상 데이터에 관한 메모리 기록으로부터 reconstruction이 이루어진다. 이를 통해 anomaly에 대한 reconstructed error는 강화된다.
MemAE는 데이터 타입에 대한 가정이 없기 때문에 일반적으로 다양한 task에 적용될 수 있다.
키워드 : autoencoder, memory
2. ANOMALY DETECTION BY LATENT REGULARIZED DUAL ADVERSARIAL NETWORK
(5.Feb.2020)

Anomaly detection은 컴퓨터 비젼 영역에서 중요한 문제이다. 정상 클래스에 속하는 다양한 범주의 이미지가 주어졌을 때, abnormal instance에 해당하는 out-of-distribution 이미지를 찾아내는 것이 목적이다. Semi-supervised GAN 기반의 방법은 최근에 anomaly detection task에서 많이 다루어졌다. 하지만, GAN을 학습하는 과정은 여전히 불안정하며 어렵다. 이러한 문제를 해결하기 위해, 새로운 adversial dual autoencoder 네트워크를 제안한다. 이 네트워크에서 학습용 데이터는 latent feature space에서 capture될 뿐만 아니라, discriminant manner로 latent representation의 공간을 제한하여 더욱 정확한 detector를 만들 수 있다. 추가적으로 discriminator로 사용되는 보조 autoencoder를 활용해서 더욱 안정적으로 학습할 수 있게 되었다.
키워드 : adversial dual autoencoder, discriminator로 사용되는 보조 autoencoder
(참고)
SOTA로 비교된 방법들
① OC-SVM/SVDD : One-class svm for learning in image retrieval
② KDE : On estimation of a probability density function and mode
③ IF : Isolation forest
④ DCAE : Stacked convolutional auto-encoders for hierarchical feature extraction
⑤ ANOGAN : Unsupervised anomaly detection with generative adversarial networks to guide marker discovery
⑥ DEEP-SVDD : Deep one-class classification
⑦ DADGT : Deep anomaly detection using geometric transformations
3. AnoGAN
(17.Mar.2017)


disease progression이나 treatment monitoring과 관련한 image markers를 capture하는 것은 어려운 일이다. 대개 자동 detection을 위해 많은 양의 데이터가 있어야 하며, 모든 데이터들은 known markers로 annotated되어 있어야 한다. annotation을 하는데 많은 노력이 필요하며 known markers도 부족할 수도 있기 때문에 이러한 방법에는 한계가 있다. 하여, 비지도 학습 방법으로 anomaly detection을 하려고 한다. AnoGAN은 deep convolutional generative adversarial network로 normal anatomical variability에 대한 manifold를 학습하며, 이미지 공장에서 latent space로 매핑하는데 새로운 anomaly scoring schema를 제안한다. 새로운 데이터가 주어졌을 때, 모델은 anomaly를 라벨링하며, image patch가 학습된 distribution과 얼마나 맞는지를 가리키는 점수 매긴다.
키워드 : GAN, residual loss, discrimination loss, learn manifold, labeling anomaly
4. Real-world Anomaly Detection in Surveillance Videos
(cvpr 2018)
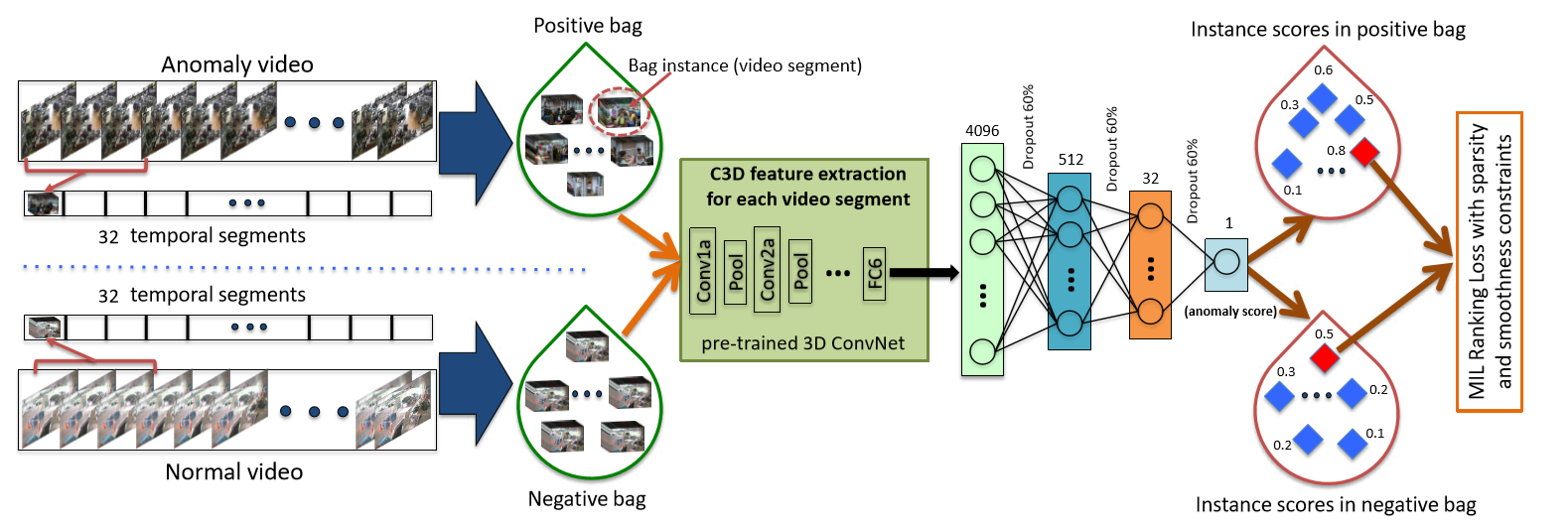
보안용 비디오에서는 다양한 현실 속의 anomaly를 포착할 수 있다. 이 논문에서 우리는 both normal and anomalous videos 모두를 통해 anomaly를 학습하는 방법을 제안한다. anomalous segment를 annotating 하는 것은 많은 시간과 노력이 필요하기 때문에 이 대신에 deep multiple instance ranking framework을 통해 anomaly를 학습하도록 하였다. 이는 약하게 라벨링된 학습용 videos를 leveraging하는 것으로 다시 말하면 clip-level이 아니라, video-level에서 라벨링을 하였다. 이 방법에서 normal and anomalous videos를 bags로 생각했고 video segments를 multiple instance learning에서의 instances로 생각했다. 그리고 anomalous video segments에 높은 anomaly score를 예측는 deep anomaly ranking model을 자동으로 학습했다. 더 나아가, ranking loss function에 공간적 리고 시간적 smoothness constraints를 두어 학습 동안에 anomaly를 더 잘 localize하도록 하였다.
키워드 : video, both normal and anomalous videos, video-level labeling
5. Future Frame Prediction for Anomaly Detection - A New Baseline
(cvpr 2018)

동영상에서의 anomaly detection은 예상되지 않은 행동을하는 event를 찾는 것을 의미한다. 하지만 존재하는 모든 방법은 minimizing the reconstruction errors of training data에서 문제가 있다. 그것은 abnormal event에서 더 큰 reconstruction error를 보장할 수 없다는 것이다. 이 논문에서는 동영상 예측 프레임워크를 사용해서 이 문제를 해결하고자 한다. 이는 abnormal event를 찾기 위해 predicted future frame과 ground truth와의 차이를 비교하는 새로운 방식이다. normal events의 고 퀄리티의 future frame을 예측하기 위해, 흔히 사용되는 appearance (spatial) constraints on intensity and gradient 방식 외에, 우리는 motion (temporal) constraint를 사용하여 예측하였다. 이를 통해 예측된 frame과 ground truth frame과의 optical flow가 일관될 수 있었다. 이 논문은 비디오 예측에 temporal constraint를 도입하는 첫번째 논문이다. 이러한 spatial and motion constraints는 빠르게 future frame prediction 을 할 수 있게 하며, 동시에 abnormal events도 빠르게 찾아낸다.
키워드 : future, video
6. MVTec AD — A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection
(cvpr 2019)

natural image에서 anomalous structure의 detection은 컴퓨터 비젼의 많은 task에서 가장 중요한 과제이다. 비지도 학습 기반의 anomaly detection 기술의 발전은 새로운 방법을 train하고 evaluate할 데이터를 필요로 한다. 우리는 5354개의 다양한 object와 texture 카데고리의 고해상도 컬러 이미지를 포함하는 MVTec Anomaly Detection (MVTec AD) 데이터셋을 제안한다.
우리는 SOTA unsupervised anomaly detection 방법들 (convolutional autoencoders, GAN, feature descriptors using pre-trained convolutional NN, classical computer vision methods)를 평가했다.
(참고)
SOTA 방법들로 언급된 모델을 참고하고자 함..
① AnoGAN
② L2 Autoencoder & SSIM Autoencoder
(Deep Autoencoding Models for Unsupervised Anomaly Segmentation in Brain MR Images,
Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders,
Auto-Encoding Variational Bayes,
I. Goodfellow, Y. Bengio, and A. Courville. Deep Learning. MIT Press, Cambridge, MA, 2016.)
③ CNN Feature Dictionary
(Anomaly Detection in Nanofibrous Materials by CNN-Based SelfSimilarity)
④ GMM based Texture Inspection Model
(Real-time Texture Error Detection on Textured Surfaces with Compressed Sensing)
⑤ Variation Model
(Variational Autoencoder based Anomaly Detection using Reconstruction Probability)
7. GANomaly
(13.Nov.2018)

Adversarial Training을 활용한 Semi-Supervised Anomaly Detection 방법.
우리는 cGAN을 사용한 고차원의 이미지 생성과 latent space의 추론을 같이 학습하는 새로운 anomaly detection 모델을 소개한다.
Generator 네트워크에서 encoder-decoder-encoder 구조를 사용함으로써 모델이 인풋 이미지를 저차원의 벡터로 잘 매핑할 수 있게 하였다. 인코더를 하나 더 추가함으써 생성된 이미지를 latent representation으로 더 잘 매핑해준다.
이미지와 latent vector 사이의 거리를 최소화함으로써 데터 분산을 학습하는 것을 돕는다. (거리가 멀면 abnormal)

키워드 : GAN, semi-supervised, cGAN, encoder 추가
8. Skip-GANomaly
(25.Jan.2019)

우리가 제안하는 방식은 skip connection이 도입된 encoder-decoder convolutional neural network으로, 고차원의 이미지 공간에서의 normal data distribution의 multi-scale distribution을 포착할 수 있게 되었다.
게다가 이 구조에 adversarial training scheme을 활용함으로써 고차원의 image space와 저차원의 latent vector space에 대해 reconstruction을 더 잘 할 수 있게 되었다.
학습 동안에 이미지와 hidden vector space 간의 reconstruction error를 최소화하는 것은 normal 데이터의 분산을 학습하는데 도움을 준다.
테스트 데이터에서 큰 reconstruction metrics는 normal 분산으로부터의 편차를 나타내고, 이것으로 anomaly를 알 수 있다.
(CIFAR-10 데이터셋에서 AnoGAN, EGBAD, GANomaly와 비했을 때, 젤 좋았음)
키워드 : skip connection, multi-scale, adversarial training
9. Adversarially Learned One-Class Classifier for Novelty Detection
(24.May.2018)
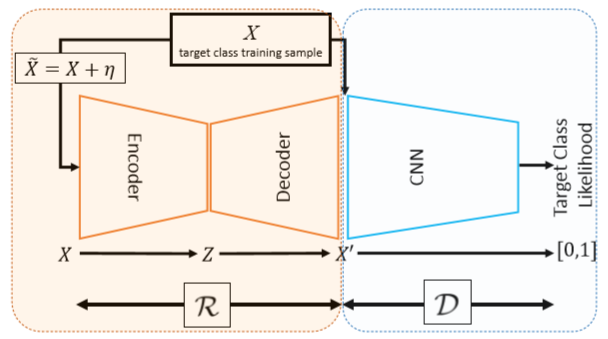
Novelty detection은 학습 데이터와 다른 데이터를 찾는 것을 의미한다. novelty class는 현실적으로 별로 없으며 잘 정의되지 않았다. 그러므로 one-class classifier가 효율적으로 이러한 문제를 모델링해준다. 그러나 novelty class에 속하는 데이터가 별로 없기 때문에 end-to-end로 네트워크를 학습하는 것은 성가신 일이다.
이 논문에서는 unsupervised, semi-supervised 방식으로 GAN을 학습하는 것에 영감을 받아서, end-to-end로 학습할 수 있는 one-class classification 구조를 제안한다.
우리의 네트워크는 두 개의 네트워크로 구성되어 있다. 각 딥 네트워크는 서로 경쟁함과 동시에 target class의 concept을 이해하고 testing samples를 분류할 수 있게 학습된다.
한 네트워크(D)는 novelty detector 역할을 하며, 다른 네트워크(R)는 inlier 샘플을 강화하고, outlier를 왜곡함으로써 이를 지원한다.
주목해 보아야 할 것은 original sample로 구분하는 것보다, 강화된 inlier와 왜곡된 outlier의 분리가 더 잘 된다는 것이다.

키워드 : GAN, inlier 강화, outlier 왜곡
끝!!
'딥러닝 > Anomaly Detection' 카테고리의 다른 글
| [Skip-GANomaly] pytorch github 실행해보기 (1) | 2020.02.24 |
|---|---|
| [Anomaly Detection] 참고 논문 리스트 (0) | 2020.02.23 |
